SQL 12일차 [모델링][속성][개념적설계]
역정규화는 무결성에 대한 책임이 따라붙는다
사원의 부서이동이 이력
속성을 만들때 고려사항
1. 엔티티가 관리할 대상인가? - >컬럼이 엔티티를 표현하는 의미를 갖는가?
2. 의미적으로 독립적인 최소 단위인가? ->한 도메인을 표현할수있는 최소단위의 컬럼인가?
3. 하나의 값만을 가지고 있는가? -> 여러개의 값을 통해서 의미를가지게 되면 원자성을 지킬 수없기때문이다.
4. 원본인가? 파생인가? -> 컬럼을 설계할때 기본 속성으로 있는 것인지 아니면 계산해서 들어가야하는 컬럼인지

분포도가 좋은 속성은 우선순위가 높다
--> 데이터가 적어야한다
분포도가 좋다 -> 식별성이 뛰어난 속성 , 값들이 반복되지 않는다 -> 이들은 기본키일 가능성이 많다 기본키는 중복 되지 않고 한 튜플을 단독으로 구별하기 때문이다.
복합키를 사용했을때 기본키의 속성 순서
1) 분포도 우선
2) 자주 조회되는 컬럼에 대해 우선순위를 부여
3) FK로 잡혀있는 PK가 조인 활용도가 높아서 우선순위가 높다

복합키 순서는 분포도가 좋은 속성을 먼저 써서 검색속도를 높인다
FK가 있는 테이블과의 조인 조회를 많이하기때문에 FK가 복합키에서 우선순위이다.
인덱스는 범위를 찾아가는 조회는 성능이 떨어진다 어차피 그 기간을 풀스캔 해야하기 때문이다.
->인덱스를 태우지 않느다.
like조회 between범위 검색을 많이 하는 컬럼은 선행컬럼으로 쓰지 않는다.
-> 패턴검색과 범위 검색은 인덱스를 태우지 않기 때문이다.

인덱스가 존재하는 이유를 부여할 수잇는 검색은 = 검색이다.
=검색을 많이 하는게 복합키에서 선행컬럼으로 오는 게 맞다
재귀적관계
아래의 대분류 중분류 소분류도 재귀를 통해서 한 테이블 안에 넣을 수있다
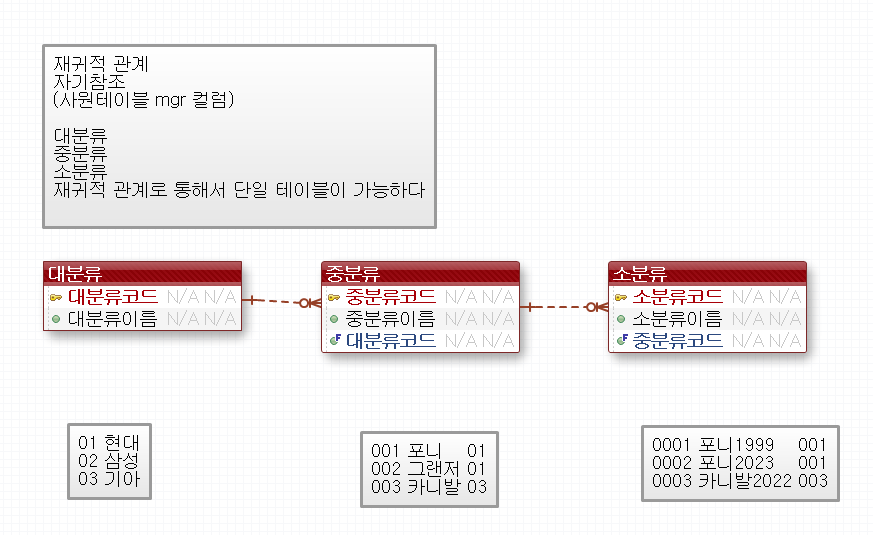
프로젝트 할때는 사원테이블의 사원번호와 관리자 정도만 알고 있으면된다.

병렬관계
하나의 테이블의 속성을 여러번참조하는 형태 -> 다른 테이블에서 자기참조 하듯이 쓰는것
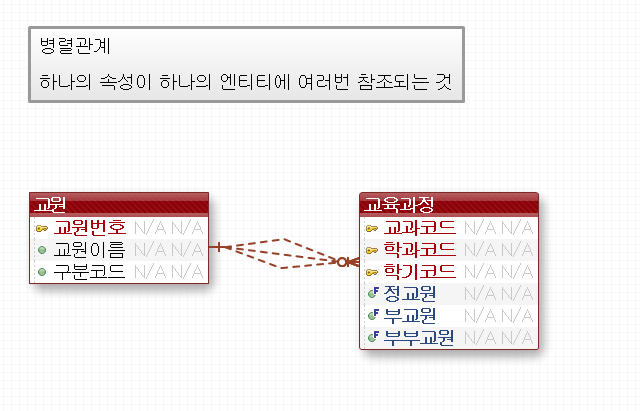
A아님 B -> 배타적 관계
배타적관계일때의 데이터 모델링 설계
슈퍼타입과 서브타입으로 나눌 수있다 -> 1:1관계임을 잘보자
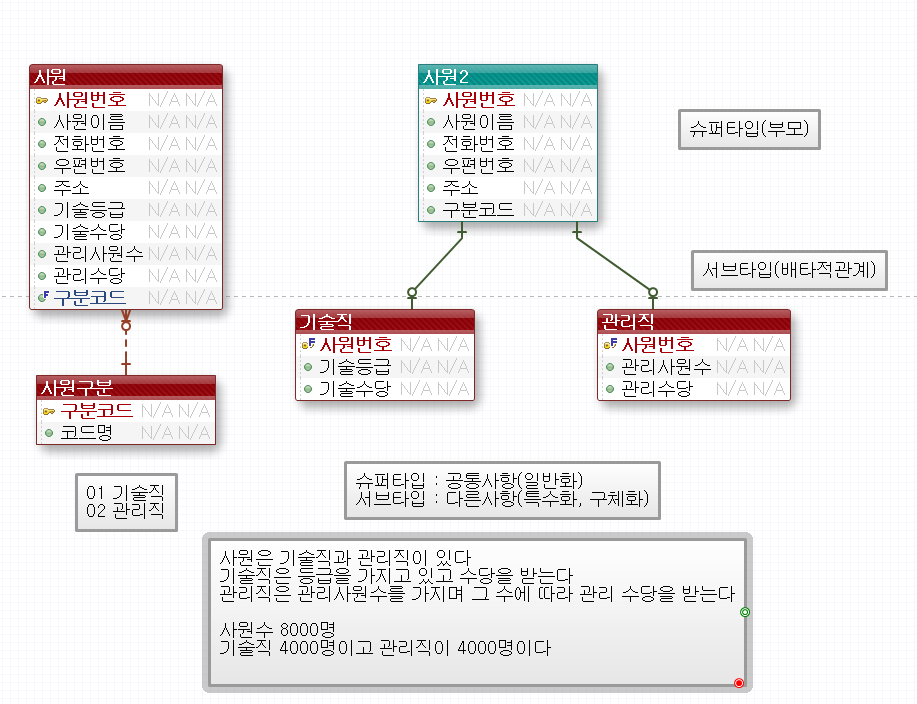
DB모델링 - 관계 (슈퍼-서브타입)
슈퍼, 서브타입 엔터티 식별자의 도메인은 반드시 같아야한다.공통된 데이터만 사원 엔터티에 남기고(슈퍼타입)기술직, 관리직만의 specialize된 속성들은 별도의 엔터티로 구성(서브타입)각 엔터
velog.io

교원과 교수, 강사의 관계도 슈퍼타입과 서브타입관계이다 구분 코드를 통해서 구분한다.
서브타입과 슈퍼타입으로 나눴던 이유! 만약 한테이블에 모두 합쳐져있고 교원의 직책이 교수이고 강사가 아니라면 강사테이블의 강사번호와 강사전화번호는 null값으로 들어가야한다 그리고 교수번호는 교수실에 종속되고 강사번호는 강사 전화번호에 종속되므로 이행적 함수종속 관계로 정규화를 필요로한다. 그리고 교수번호에 종속되는 컬럼들을 주렁주렁 확장시키고 싶을 수 있다. 그럴때는 이렇게 테이블을 나눠서 확장성을 준다. 왜냐면 해당하지 않으면 다 null값 들어가는 것보다 해당할때만 튜플을 삽입하는 것이 낫기 때문이다.

관계
fK가 비식별로가면 중복가능
PK로 식별로가면 중복불가능
카페형게시판 참조
create table 하지 않아도 됨

처음에 할때는 한 게시판 마다 모두 create table을 해주는게 나음
하지만 관리는 불편하겠지 하나만들때마다 create해줘야하니가
식별은 된다
설문지번호와 문제번호로 문제를 구별할수 있기때문에

비식별은 안된다 설문지 번호에 따라 문제번호가 중복나올수 있기때문에
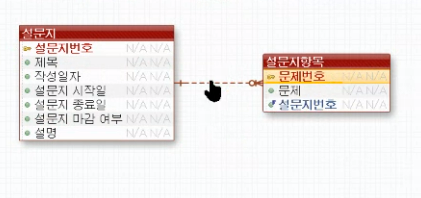
설문지에 대한 DB모델링
설문지를 dB모델링하는게 가장까다롭다 설문지별 문제 번호를 관리하고 있어야하고 설문지별 문제 번호별 문항번호도 관리 해야한다. 데이터가 들어갈때 1번 설문지의 문제1번 1번문항을 넣자고 보면 이렇게 1,1,1|1,1,2|이런식으로 들어가야하기 때문에 데이터 insert가 헷갈리고 관리하기 힘들다 시험지도 이런식으로 관리해야하는데 그때는정답까지 관리해 줘야해서 더 테이블 설계가 어렵다.
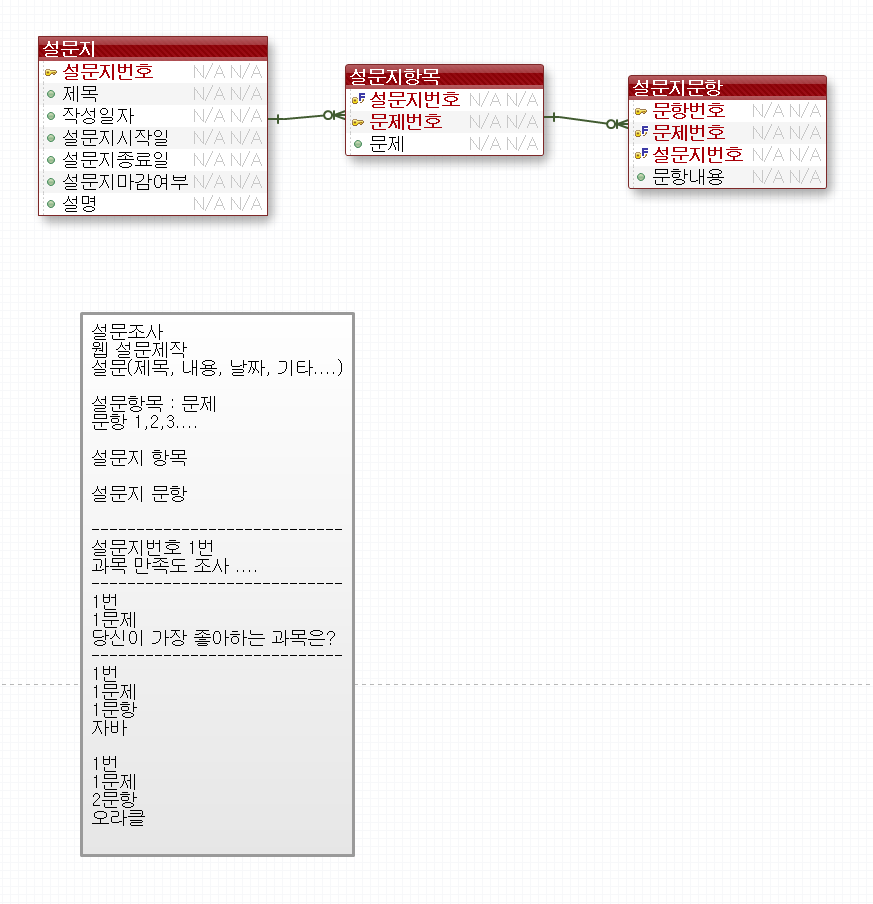
그룹웨어 ERD모델링하기 참조
https://forest71.tistory.com/163
그룹웨어 (Java) - 설치
조직(기업) 구성원의 협업 지원 소프트웨어인 그룹웨어9(Groupware9)은 과제 관리 시스템 PMS9 (Project Management System)에 이은 두번째 프로젝트로 빠른 개발을 위해 만든 Java 웹 프로젝트 템플릿인 Project
forest71.tistory.com
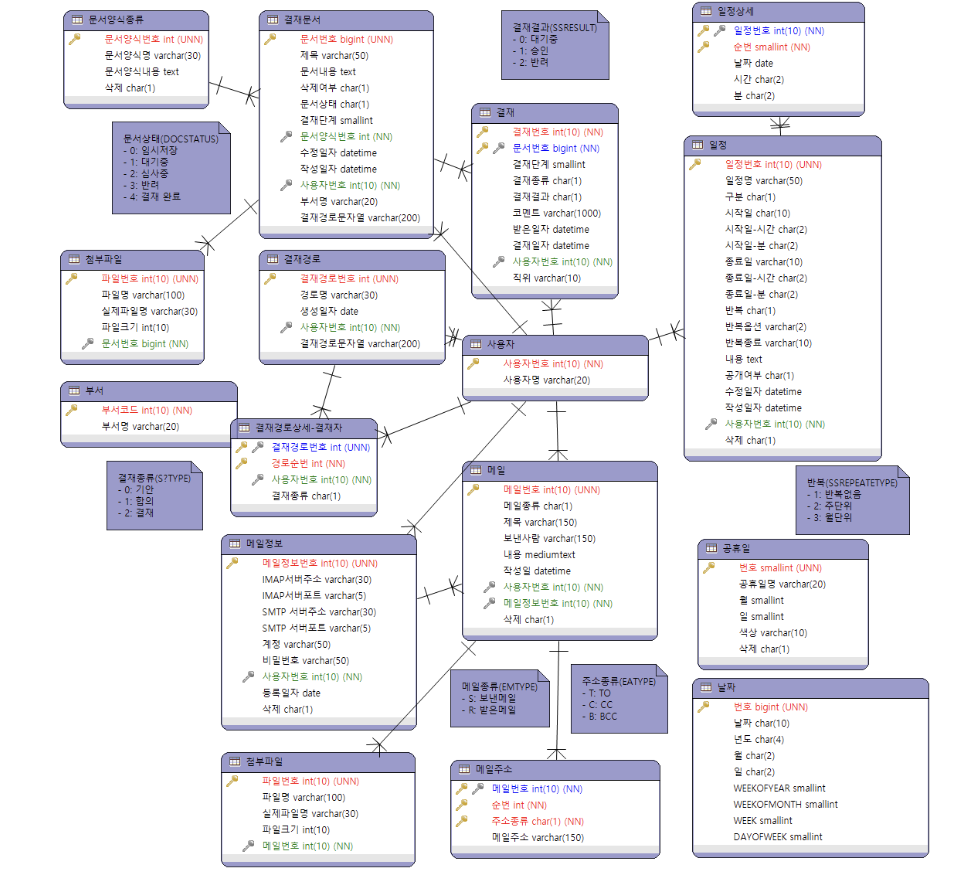
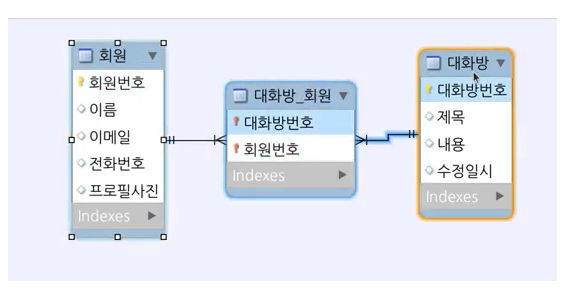
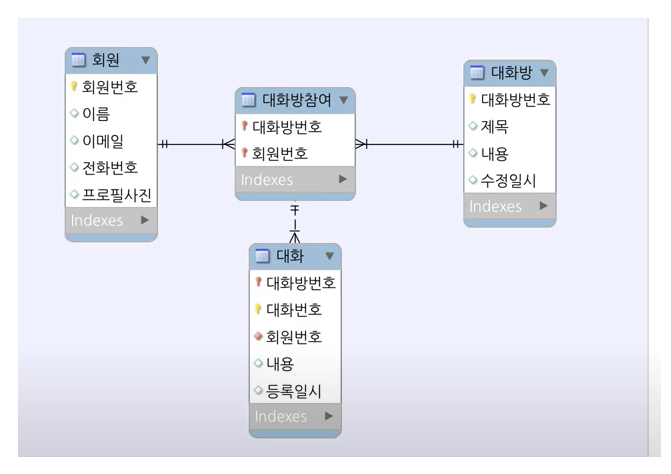
카카오 채팅 ERD 샘플 참조
객체 DB로 보통 채팅을 관리하고 관계형 DB로는 관리 하지 않음
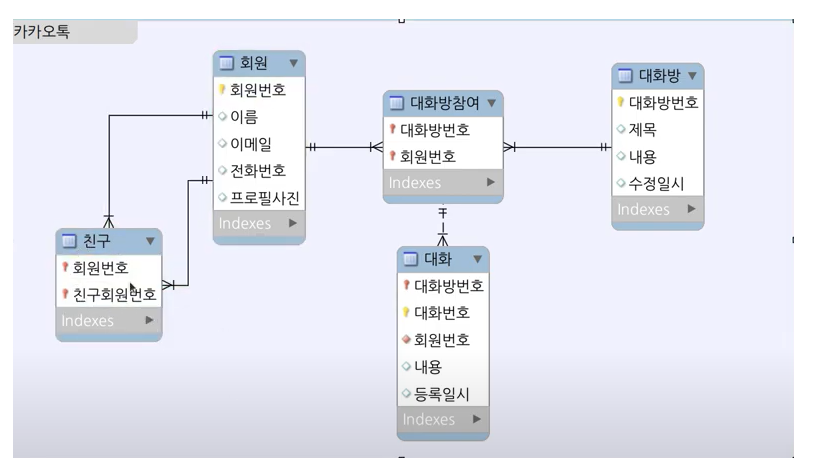
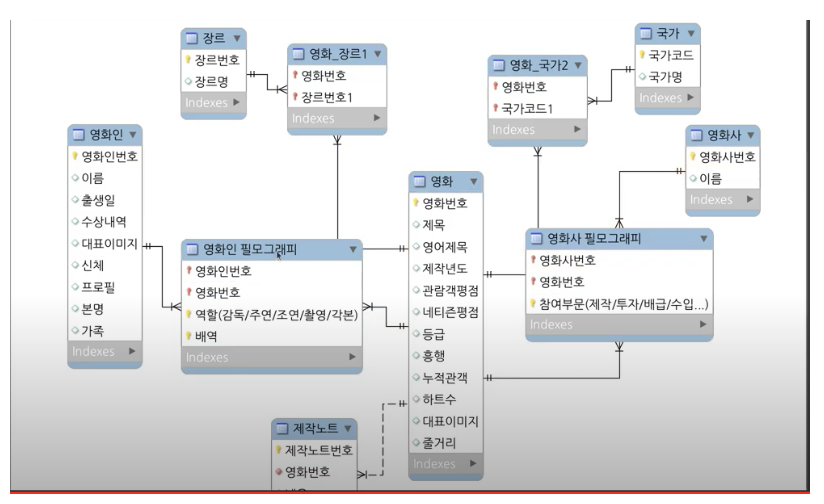
네이버 영화 모델링
개념적 모델링 끝
논리적 모델링
개념적인 걸 가지고 매핑한다
엔티티를 구성하는 속성간의 중복을 제거 하여 데이터 베이스를 최적화
중복을 제거하려면 테이블을 나눠야한다
이상현상을 판단한다
입력 이상
수정이상
삭제 이상
정규화

1정규화
중복속성 제거
주문번호, 수출여부 고객번호 우선순위 주문수량을 넣기 위해서 제품번호 제품명 재고수량이 중복해서 들어가야한다. 키에 종속되어있는 컬럼을 제외하고 나머지 컬럼은 다른 테이블을 생성해서 중복속성때문에 발생하는 문제를 해결한다.


입력이상: 주문이 발생되어야만 제품정보를 등록할 수 있다.
수정이상: 마우스의 수량을 9702에서 15000으로 변경하고자 한다면 데이터를 3번 수정해야한다.
삭제이상 ; 제품번호가 1201인 스피커를 주문한 내역을 삭제하면 제품명, 재고수량 정보도 모두 삭제된다.

2정규화
키에 의존하긴하는데 복합키일때 둘 중 하나의 키에만 의존하는 경우


부분함수 종속 제거
복합키일때만 사용한다고 보면된다. 주문번호로는 수출여부, 고객번호, 사업자번호, 우선순위 주문수량을 결정한다. 두개의 테이블로 나누고 N:M 관계를 설정해주면 복합키를 단일키로 구분하는 테이블을 만들 수있다.

3정규화
키가 하나만 있을때 적용하는 정규화
기본키에 의존적이지 않은애들 제거
다른 속성이 의존하는 것!
실무에서는 여기까지만 하고 나머지는 역정규화한다
여기서는 고객 번호가 사업자번호 우선순위 수출여부를 결정하고 주문번호와 제품번호를 통해서 주문수량을 결정한다.
주문목록 테이블을 둘로 쪼갠다

QUIZ
아래 테이블을 정규화하시오

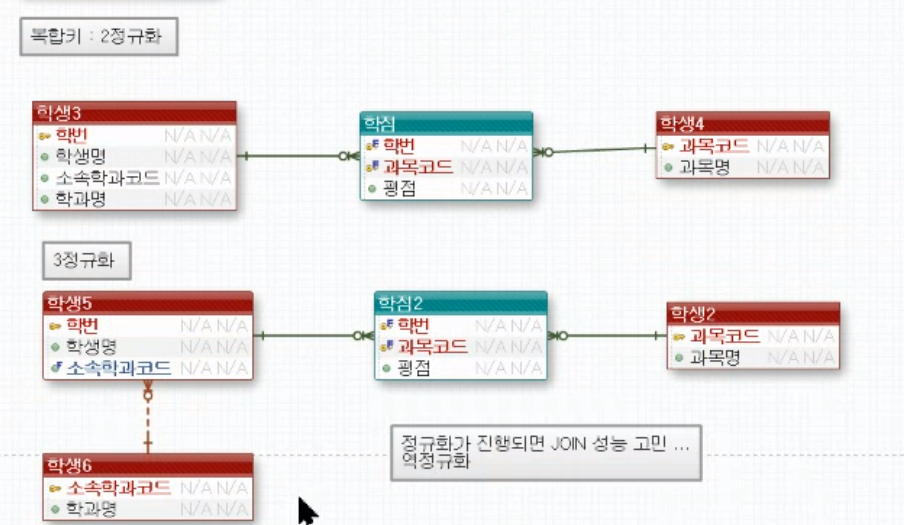
1정규화는 기본상식을 해결해서 보통 현업에서는 2,3정규화를 진행한다
https://parkadd.tistory.com/115
글 조회시 조회수 중복 증가 방지를 위해 Session VS Cookie
팀 프로젝트를 진행하면서 글의 조회수를 조작해서 방금 올렸던 글을 자기 자신이 100번 새로고침하면 조회수가 100회가 되는 마술이 있었습니다. 따라서 글의 조회수 중복 증가를 방지하지 위해
parkadd.tistory.com